


怎样界定「深度学习」?「深度学习」跟人工智能化的关联是哪些的?
什么叫 “深度学习”,学术界并未有统一的界定。但有两个界定尤其非常值得掌握:一个来源于卡内基梅隆高校的Tom Mitchell专家教授,一个来源于Goodfellow、Bengio 和 Courville共同编撰的的經典“花书”《深度学习》。
Tom Mitchell:依据提升全过程抽象性界定深度学习
第一个界定,来源于zhu名的电子计算机生物学家、深度学习学者,卡内基梅隆高校的 Tom Mitchell 专家教授。针对某种每日任务 T 和特性衡量 P专业微信拉票群,假如一个计算机语言在 T 内以 P 考量的特性伴随着工作经验 E 而完善自我,那麼大家称这一计算机语言在从工作经验 E 中学习培训。[1]
Mitchell 的这一界定在深度学习行业是大家都知道的,而且承受了時间的磨练。这句话此次出現在他 1997 年出版发行的 Machine Learning 一书里。
在 Goodfellow, Bengio & Courville 近期出版发行的权威性经典著作《深度学习》(Deep Learning) 的第 5 章中,这一段引用文献也占有了首要地位专业微信拉票群,变成此书对学习培训优化算法的表述的立足点。
下面的图是 Mitchell 界定的图例:
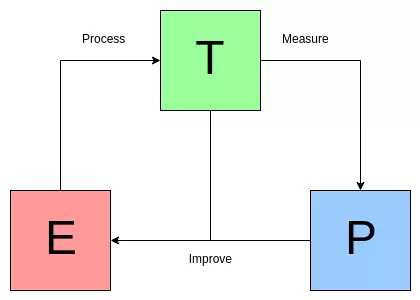 The Mitchell Paradigm
The Mitchell Paradigm
“花书”《深度学习》:论测算在深度学习中的必要性
说到 Goodfellow、Bengio 和 Courville,就迫不得已提她们共同编撰的的《深度学习》,这本书对深度学习是那样界定的:深度学习实质上归属于应用统计学,大量地关心怎样用电子计算机统计分析地可能繁杂涵数,不太关心为这种涵数出示置信区间。[2]
Mitchell 对设备学习的定义在运用中已不可用;它偏重于提升全过程的实际构成部分,这种构成部分一般与深度学习相关,但它沒有要求应当怎样结合实际贴近它。
《深度学习》中对设备学习的定义在实质需要标准得多,它强调数学计算获得了运用 (事实上注重了对数学计算的应用),而传统式的统计分析定义置信区间则已不注重。深度学习有什么优化算法?
深度学习优化算法能够分成三个大类 —— 无监督学习、无监督学习和增强学习。无监督学习,对训炼有标识的数据信息有效,可是针对别的沒有标识的数据信息,则必须预计。无监督学习,用以对无标识的数据(数据信息沒有预备处理)的解决,必须挖掘其中在关联的情况下。增强学习,接近彼此之间,尽管沒有精确的标识或是错误报告,可是针对每一个可预测分析的流程或是个人行为,会出现某类方式的意见反馈。
下边详细介绍无监督学习和无监督学习的十大常用算法:无监督学习
1. 决策树算法 (Decision Trees)
决策树算法是一个管理决策适用专用工具,它用树型的图或是模型表示管理决策以及很有可能的不良影响,包含相互独立的危害、資源耗费、及其主要用途。可以看下面的图,随便感受一下决策树算法长那样的:

从商业服务角度观察,决策树算法便是用至少的 Yes/No 难题,尽量地作出一个恰当的管理决策。它使我们根据一种结构型、专业化的方法解决困难,获得一个有逻辑性的结果。
2. 朴素贝叶斯归类 (Naive Bayes Classification)
朴素贝叶斯支持向量机是一类简易几率支持向量机,它根据把贝叶斯定理应用在特点中间关联的强自觉性假定上。下面的图是贝叶斯公式 ——P (A|B) 表明后验概率,P (B|A) 表明似然度,P (A) 表明类型的先验概率 (class prior probability),P (B) 表明作出预测分析的先验概率 (predictor prior probability)。
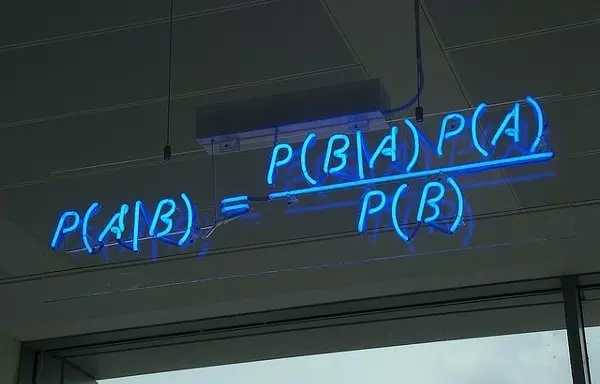
现实生活中的运用事例:一封电子邮件是不是垃圾短信一篇文章应当分到高新科技、政冶,還是体育专业一段文字表述的是积极主动的心态還是消沉的心态?面部识别
3. 一般最小二乘重归 (Ordinary Least Squares Regression)
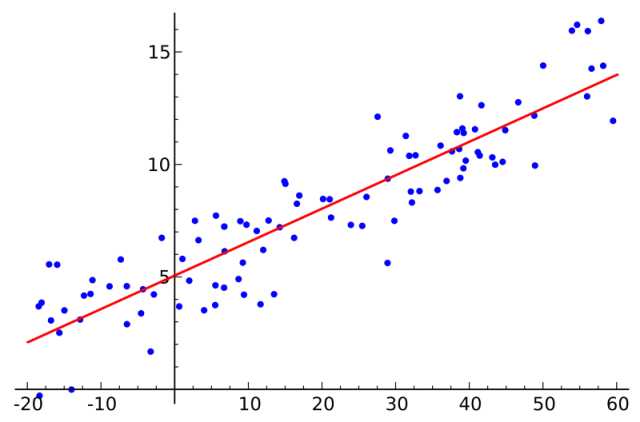
假如你学过统计学,你很有可能听过线性回归。最少最小二乘是一种开展线性回归的方式。你能觉得线性回归便是让一条平行线用最合适的姿态越过一组点。有很多方式能够那样做,一般最小二乘法如同那样 —— 你能画一条线,精确测量每一个点至这根线的间距,随后加起來。最好是的线应该是全部间距加起來最少的一根。
线形法表明模型线性模型,而最小二乘法能够降到最低该线性模型的出现偏差的原因。
4. 逻辑回归 (Logistic Regression)
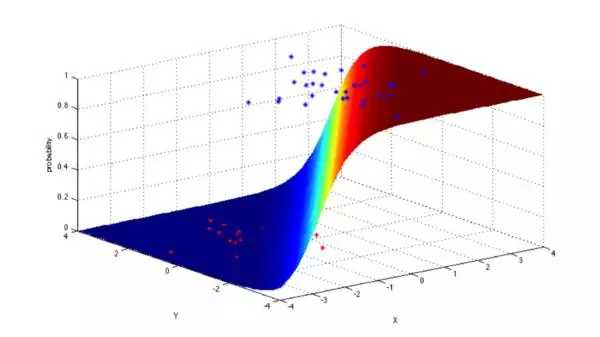
逻辑回归是一种十分强劲的统计分析方法,能够把有一个或是好几个自变量的数据信息,创建为二项式种类的实体模型,根据用积累逻辑性遍布的逻辑函数可能几率,精确测量归类自变量和一个或好几个单独自变量中间的关联。
一般,重归在现实生活中的主要用途以下:信用评级精确测量网络营销的取得成功度预测分析某一商品的盈利特殊的某一天是不是会发生地震
5. svm算法 (Support Vector Machines)

SVM 是一种二分优化算法。假定在 N 维空间,有一组点,包括二种种类,SVM 形成 a (N-1) 维的超平面,把这种点分为2组。例如给你一些点在纸上边,这种点是线形分离出来的。SVM 会寻找一个平行线,把这种点分为两大类,而且会尽量杜绝这种点。
从经营规模来看,SVM(包含适度调节过的)处理的一些超大的难题有:广告宣传、人类基因组剪辑结构域鉴别、根据照片的性別检验、规模性图片分类…
6. 集成化方式 (Ensemble Methods)
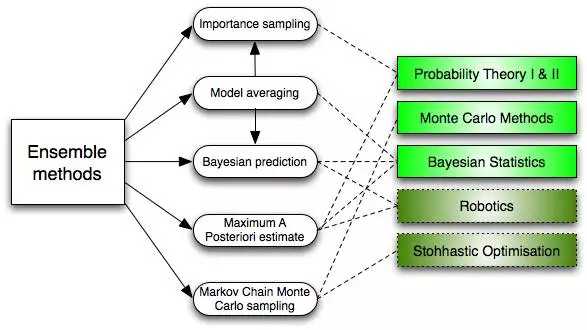
集成化方式吸收了许多 优化算法,搭建一个支持向量机结合,随后给他们的预测分析带权重值的开展投票,进而开展归类。最开始的集成化方式是贝叶斯算法平均法 (Bayesian averaging),可是近期的优化算法集还包含了改错輸出编号 (error-correcting output coding) ,bagging 和 boosting
那麼集成化方式怎样工作中的?为何他们比独立的实体模型更强?他们平衡了误差:如同假如你平衡了很多的趋向民主党派的投票和很多趋向美国民主党的投票,你都会获得一个不那麼片面性的結果。他们减少了标准差:结合很多实体模型的参照結果专业微信拉票群,噪声会低于单独实体模型的单独結果。在金融业上,这叫项目投资分散化标准 (persification)—— 一个配搭很多种多样个股的资产配置,比独立的个股更少不幸。他们不大可能过度拟合:假如给你独立的实体模型并不是彻底线性拟合,你融合每一个简易方式模型,就不容易产生过度拟合 (over-fitting)无监督学习
7. 聚类算法 (Clustering Algorithms)
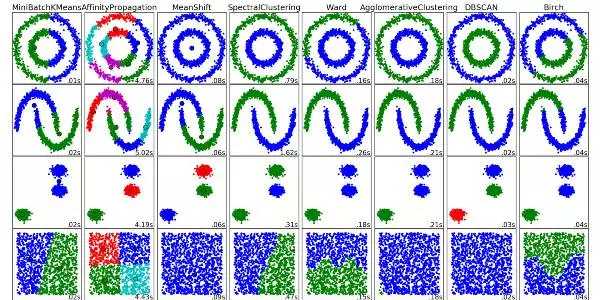
聚类算法便是把一组目标排序化的每日任务,促使在同一组的目标相比其他组的目标,他们相互更为类似。
每个聚类算法都不一样,下边是在其中一些:根据图心(Centroid)的优化算法根据联接的优化算法根据流动量的优化算法摡率论特征提取神经元网络 / 深度神经网络
8. 主成分分析法 (Principal Component Analysis)
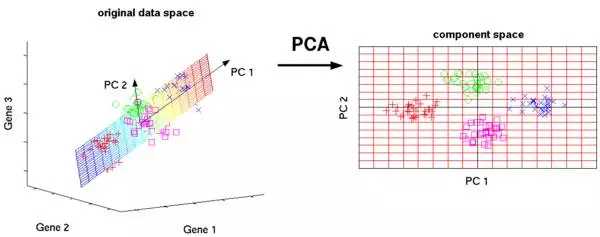
PCA 是一种统计分析全过程,它根据正交变换把一组很有可能关联的自变量观查,转化成一组线形非有关的自变量的值,这种非有关的自变量便是主成份。
PCA 的运用包含缩小、简单化数据信息使之便于学习培训,数据可视化。必须留意的是,当决策是不是用 PCA 的情况下,行业专业知识尤其关键。它不适感用以噪声多的数据信息(全部成份的标准差要很高才行)
9. 奇异值分解 (Singular Value Decomposition)

离散数学中,SVD 是对一个尤其繁杂的引流矩阵做因式分解。例如一个 m*n 的引流矩阵 M,存有一个溶解如 M = UΣV,在其中 U 和 V 是酉矩阵,Σ 是一个对角矩阵。
PCA 实际上是种简易的 SVD。在电子计算机图型行业,第一个人脸识别优化算法就用了 PCA 和 SVD,用特点脸 (eigenfaces) 的线形融合表述面部图象,随后特征提取,用简易的方式把面部与人搭配起來。虽然现如今的方式更为繁杂,仍然有很多是借助相近那样的技术性。#p#分页标题#e#
10. 单独化学成分分析 (Independent Component Analysis)

ICA 是一种统计分析技术性。它挖掘随机变量、精确测量数据信息或是数据信号的结合中暗含的要素。ICA 界定了一种通用性实体模型,用以观察到的多自变量数据信息,一般是一个极大的样版数据库查询。在这里一实体模型中,假定数据信息自变量是一些不明的、潜在性的自变量的线性组合,而组成方法也是不明的。另外假定,潜在性的自变量是是非非伽马分布且独立同分布的,大家称作观察数据信息的单独成份 (Independent components)。
ICA 与 PCA 有一定关系,可是一种更为有效的技术性,在經典方式彻底无效的情况下,能够发觉数据库中的潜在性要素。它的运用包含数字图片,文档数据库查询,经济指数和心理测量。
参照连接:
[1]【技术性必需】讲解十大深度学习优化算法以及运用